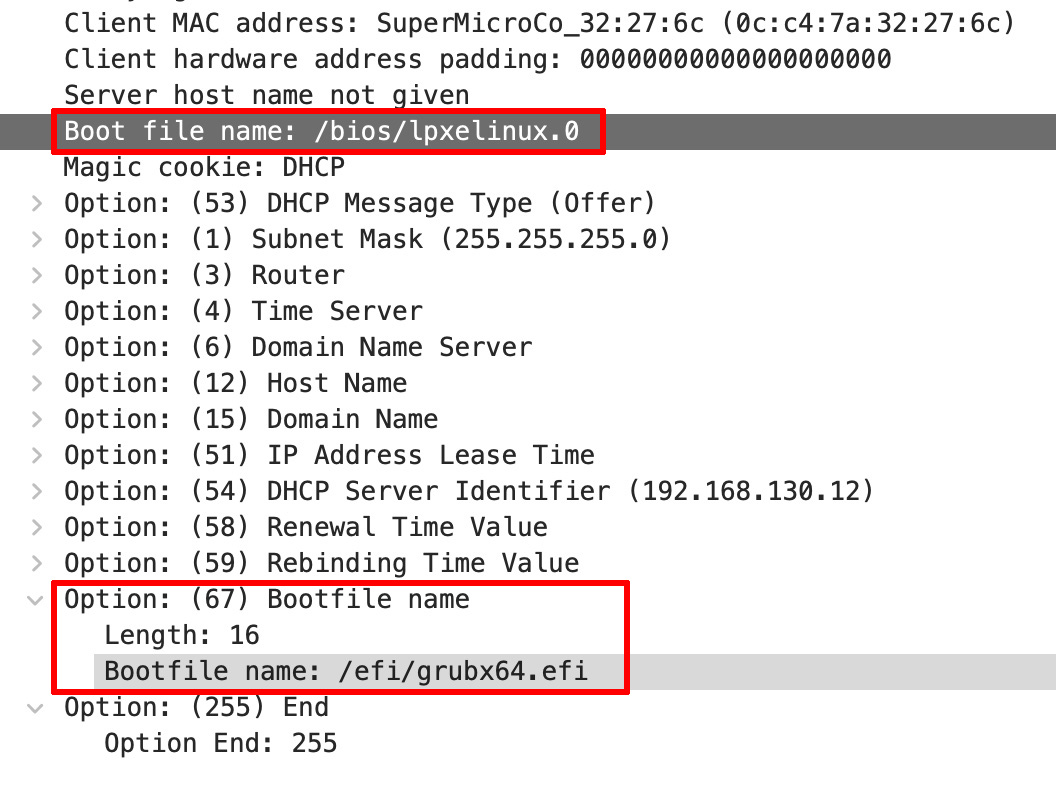
DHCP OFFER with both lpxelinux.0 and grubx64.efi boot-file-names
TIL a DHCPv4 server can respond with two different TFTP boot-file-names in a single DHCPOFFER packet. And how the second filename can get corrupted with extra junk that shows up as a PXE client trying to download a slightly wrong file from your TFTP server.
TL;DR: Supermicro UEFI firmware has dodgy PXE TFTP implementation, combined with putting boot file name as option 67 instead of the “file” field in a DHCP OFFER causes it to read trash as a filename. Also in Kea DHCP some subtle differences in behavior of “boot-file-name” when used as a config directive and an option. The latter of which can cause two boot file names to be presented to PXE clients.
TL;DR 2: Buggy UEFI firmware isn’t obeying the format of DHCP options in the packet. It should be reading in X number of bytes for input, but it overruns and then tries to request garbage. This is NOT a DHCP server nor TFTP server bug, but buggy UEFI firmware.

TFTP request with 0xFF at the end of the filename
The latter I’ve seen before but I don’t think I actually dug into trying to figure it out. Again, more interesting stuff I’ve uncovered switching from ISC DHCP to ISC Kea. Here I will try to explain where the mangled TFTP filename came from and how to avoid it.
I was trying a DHCPv4 server configuration to support both UEFI PXE clients and some old legacy BIOS-based motherboards. In old ISC DHCP this is usually done with a class to match on the vendor class or the processor architecture (code 93). If it’s 0x00 0x07, return in the DHCP OFFER a file-name of a UEFI network boot program such as syslinux.efi or bootx64.efi, else return a file-name of something like lpxelinux.0:
# ISC DHCP
class "pxeclients" {
match if substring (option vendor-class-identifier, 0, 9) = "PXEClient";
if option arch = 00:07 {
filename "/efi64/syslinux.efi";
} else {
# PXELINUX >= 5.X is the new hotness with HTTP/FTP
filename "/bios/lpxelinux.0";
}
}
I was trying to do this same thing over in ISC Kea using a client-class:
"Dhcp4": {
...
"boot-file-name": "/bios/lpxelinux.0",
"next-server": "192.168.130.10",
...
"client-classes": [
{
"name": "grubx64_efi",
"test": "option[61].hex == 0x0007",
"option-data": [
{
"name": "boot-file-name",
"data": "/efi/grubx64.efi"
}
...
...
Except when I tried to UEFI PXE boot my system over IPv4, two unexpected things happened:
TFTP request with 0xFF at the end of the filename

Wireshark from the tftp server showing the request filename
First, the UEFI TFTP client was asking for a filename with extra characters (0xFF) at the end. This showed up in both syslog for the tftp server as well as a packet capture on the tftp server showing the extra 0xFF at the end. Others on the internet have mentioned other termination characters such as unicode U+FFFD. This was causing PXE booting to fail because the target system couldn’t fetch the bootloader program. In this case I’m still testing with a SuperMicro A1SAi motherboard as prior posts.
Second, when I ran packet captures to verify the filename being sent in the DHCP OFFER to make sure it wasn’t garbage, there were TWO boot filenames being returned in two different spots in the same packet! Both my /bios/lpxelinux.0 and /efi/grubx64.efi paths were being offered. wtf?
I started searching around and found these two enlightened threads on the Mikrotik forums and on the Ubiquiti forums that addressed my weird filename format. Others have seen this behavior too, and it shed some light on the problem. It comes down to if the boot file-name was included as an option (this part is key, in this case option 67) then UEFI PXE TFTP implementations expecting it to be a null-terminated string like, whereas the DHCP server terminated the field with an end-of-options flag of 0xFF. In other words, the UEFI should be respecting the data length field and terminating the string appropriately and not read too-many bytes.
Thus what I was seeing was the UEFI firmware reading beyond the expected end of the filename, including the marker and then trying to TFTP request the file “grubx64.efi<FF>”.
This got me into reading up on the format of DHCP OFFER packets and I discovered the second issue. In RFC2131, DHCP OFFER headers have fix-length fields for “siaddr“, the “next-server” or TFTP server IP address, “sname“, an optional server hostname, and “file“, a 128-byte field that holds a boot filename. These fields are null-terminated.

RFC2131 DHCP format
HOWEVER, in RFC2132 which lays out the various DHCP options that can be specified we get to option 67. This specifies a DHCP Option “is used to identify a bootfile when the ‘file’ field in the DHCP header has been used for DHCP options.” Here the raw format is 0x67 + the length of the filename + filename. Note the lack of null termination used.
The way I read the RFC this says the TFTP filename can either be in the original DHCP OFFER header, a/k/a the “fixed fields” or specified later as an variable-length DHCP option, but not both at the same time.
This seems to be a source of a lot of confusion for people trying to troubleshoot their PXE boot configurations. It seems many like myself do not know there are two fields and keep hammering away fiddling with filenames and it’s not clear which one they’re setting.
Bonus: see below when I try to add on some dummy Option 68 data, still breaks
This got me back to reading the Kea docs again to find out what was wrong with my configuration. I caught on to the fact I was using a global “boot-file-name” and then specifying “boot-file-name” again as option 67 in my client-class.
They configuration options in Kea are literally named same thing and should be the same thing, right? RIGHT??
No, it turns out buried in 8.2.18.1 Setting Fixed Fields in Classification they are very much different. It turns out in order to set the boot-file-name set in the OFFER header, I needed to ditch the options-data and re-set “boot-file-name” again in the right scope like this:
"Dhcp4": {
...
"boot-file-name": "/bios/lpxelinux.0",
"next-server": "192.168.130.10",
...
"client-classes": [
{
"name": "grubx64_efi",
"test": "option[61].hex == 0x0007",
"boot-file-name": /efi/grubx64.efi" <<< note not in an option-data block
}
...
...
I guess technically if the header was full then it would make sense to call this field the same name since it should serve the same purpose.
Also for whatever reason the examples in the Kea documentation mention things like "boot-file-name": "/dev/null" which might lead you to believe this leaves the field empty. But no, it quite literally sends the string /dev/null as the filename sent to the target server in the DHCPOFFER.
Winning!
This gets us back to returning a single TFTP boot file-name in the first part of the DHCP OFFER packet, it’s null-terminated, and when the target system UEFI PXE boots, it’s requesting a valid filename. And in this case the client-class test does the right thing, it detects the target system is UEFI and sends the /efi/grubx64.efi boot-file-name instead of /bios/lpxelinux.0. Winning!
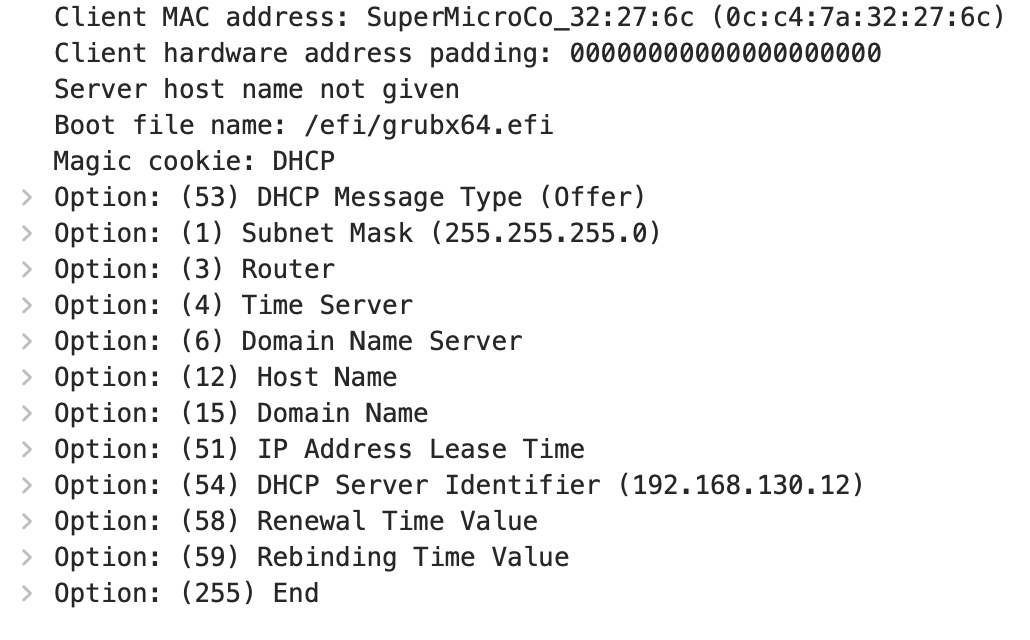
Wireshark of DHCP OFFER with only grubx64.efi
and here’s the happy server:
>>Checking Media Presence......
>>Media Present......
>>Start PXE over IPv4.
Station IP address is 192.168.135.28
Server IP address is 192.168.130.10
NBP filename is /efi/grubx64.efi
NBP filesize is 2541096 Bytes
>>Checking Media Presence......
>>Media Present......
Downloading NBP file...
Succeed to download NBP file.
But why?
While this fixes my problem, it doesn’t address the seeming impedance mismatch between what DHCP RFCs say how the filename is specified and why UEFI seems to do its own thing by tacking on extra characters such as 0xFF. Surely these two standards groups must talk to each other?
Cracking open the UEFI 2.6 Specification, my favorite reading as of late, it’s mentioned in “Network Protocols – ARP, DHCP, DNS, HTTP and REST”. Here in EFI_DHCP4_HEADER it mentions BootFileName[128]. Then right after in EFI_DHCP4_PACKET_OPTION it clearly mentions the format of “option code + length of option data + option data”. So the format of options as mentioned in RFC2131/2132 is acknowledged here. But it really doesn’t mention line terminations, and I assume that’s left as an implementation detail.
PXE Specification doesn’t really mention line terminations either.
RFC2132 clearly states that we shouldn’t be adding our own null termination in DHCP Options. That is, we shouldn’t be trying to set boot-file-name to something like “/efi/grubx64.efi\0” in attempt to trick the UEFI into using the “correct” filename.
Options containing NVT ASCII data SHOULD NOT include a trailing NULL; however, the receiver of such options MUST be prepared to delete trailing nulls if they exist. The receiver MUST NOT require that a trailing null be included in the data. In the case of some variable-length options the length field is a constant but must still be specified.
The open source UEFI reference implementation, Tianocore EDK II, takes the stance RFC2132 says it’s not guaranteed to be null terminated, which seems to conflict with this paragraph that says the option shouldn’t ever be null terminated to begin with. In any case, they take the boot-file-name from the DHCP OFFER and if it’s Option 67 they use the length of the string to null-terminate it, else if it’s the fixed-field just use it directly: (NetworkPkg/UefiPxeBcDxe/PxeBcDhcp4.c)
//
// Parse PXE boot file name:
// According to PXE spec, boot file name should be read from DHCP option 67 (bootfile name) if present.
// Otherwise, read from boot file field in DHCP header.
//
if (Options[PXEBC_DHCP4_TAG_INDEX_BOOTFILE] != NULL) {
//
// RFC 2132, Section 9.5 does not strictly state Bootfile name (option 67) is null
// terminated string. So force to append null terminated character at the end of string.
//
Ptr8 = (UINT8 *)&Options[PXEBC_DHCP4_TAG_INDEX_BOOTFILE]->Data[0];
Ptr8 += Options[PXEBC_DHCP4_TAG_INDEX_BOOTFILE]->Length;
if (*(Ptr8 - 1) != '\0') {
*Ptr8 = '\0';
}
} else if (!FileFieldOverloaded && (Offer->Dhcp4.Header.BootFileName[0] != 0)) {
//
// If the bootfile is not present and bootfilename is present in DHCPv4 packet, just parse it.
// Do not count dhcp option header here, or else will destroy the serverhostname.
//
Options[PXEBC_DHCP4_TAG_INDEX_BOOTFILE] = (EFI_DHCP4_PACKET_OPTION *)
(&Offer->Dhcp4.Header.BootFileName[0] -
OFFSET_OF (EFI_DHCP4_PACKET_OPTION, Data[0]));
}
So at least their implementation does the right thing as far as we’re concerned, and not feeding tailing characters to the TFTP server.
I know this isn’t the case of the UEFI on my SuperMicro test motherboard. If there’s a boot file name in option 67, it’s gonna get screwed up.
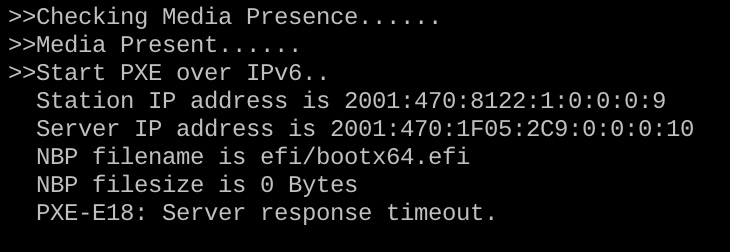
Notably this doesn’t seem to be a problem with DHCPv6 and PXE booting as DHCPv6 doesn’t use the same sort of fixed fields in DHCP ADVERTISE messages.
Further testing overruns with option 68
12/9: I wondered what happened if I added yet another option to my OFFERs that was right after Option 67. Would the UEFI loader figure out where to stop trying to read option 67, or would it keep reading beyond the end of the field? I configured Kea to send option 68, for “Mobile IP Home Agent”. The name and purpose doesn’t matter, I just wanted the next numerical option so the data would be adjacent in the packet.
Here’s what the new OFFER looks like with some dummy option 68 data:
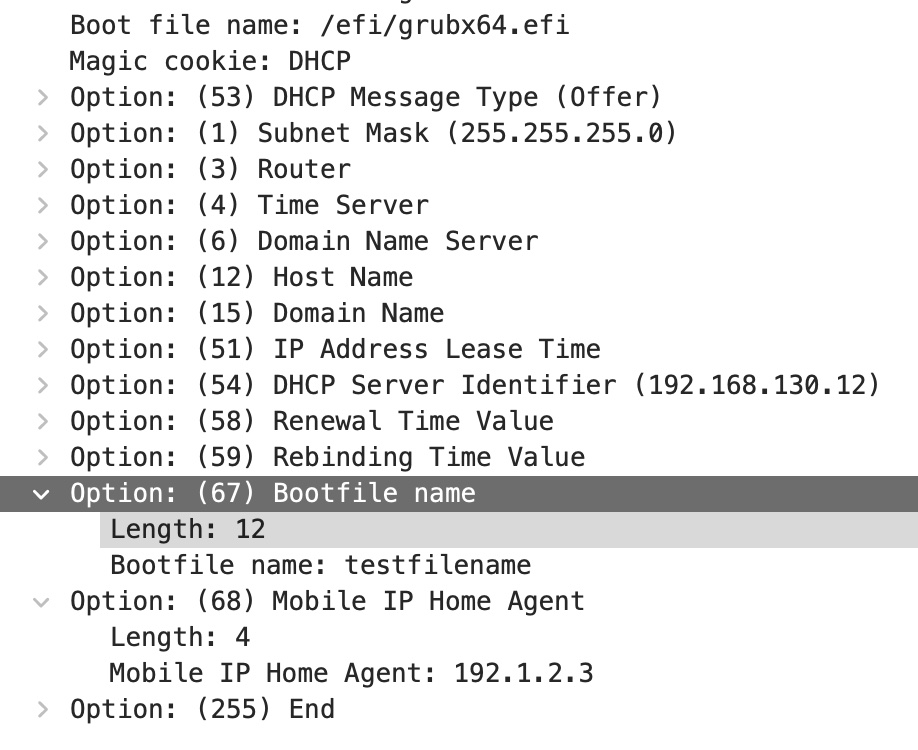
DHCP OFFER with filename, Option 67, and Option 68
and here’s the hex representation of it in the packet:

Hex payload of Option 67 and 68
We have 0x43 (Decimal 67 for option 67), length 12, “testfilename”. Then immediately after we have 0x44 (Decimal 68 for option 68), length 4, followed by bytes of an IPv4 address c0-01-02-03 (192.1.2.3), and finally our 0xFF end terminator.
What does the Supermicro UEFI TFTP client do? It surprisingly reads beyond the end of option 67 and keeps going and using option 68 data as the TFTP boot-file-name! All the way to the end of the DHCP packet again, including the 0xFF terminator.

UEFI reading both option 67 and 68 data for boot-file-name!
This shows up in the TFTP server log as the original “testfilename” and then the ASCII representation of the option 68 data.
I call this a UEFI firmware bug. The spec says the firmware should read in the length and then read that many bytes in. The firmware authors just read input until they can’t read anymore, blissfully reading in way more than they should.
To be clear this is not a TFTP server nor a DHCP server bug! The DHCP server is faithfully returning the filename you configured it to serve, and the TFTP server is faithfully trying to serve up the file that was requested of it. Problem is the UEFI firmware is trying to fetch the wrong name.
Conclusions and workarounds
The TFTP filename getting stuff appended to the end seems to be yet another UEFI implementation bug as others on the internets claim. It would seem if you’re having this problem, your best bet is to avoid using DHCP Option 67 and work to configure your DHCP server so your boot-file option is being set in the DHCP OFFER header directly. In ISC DHCP this seems to be the plain “filename” directive. In ISC Kea, it’s the top-level “boot-file-name” as mentioned above. In dnsmasq (I haven’t personally tested this) it seems to be the “dhcp-boot” directive.
The Windows DHCP server seems to be a big source of confusion. Practically every example I find for Windows Deployment Services says to use Option 67, I’m not even sure if there’s a way to set the field in the header. I don’t have a Windows server handy to look at for reference.
The only advantage I can see to using Option 67 over the fixed-field name is that the fixed-field name is limited to 127 bytes, whereas Option 67 allows up to 255 bytes.
Another option is to UEFI PXE boot over IPv6 which avoids this problem altogether.
There’s certainly some clever workarounds out there such as making symlinks on the TFTP server so that for example “grubx64.efi<FF>” links to “grub64.efi”. While that may work it seems too hackish even for me.
There may be a possibility of other UEFI things out there that need to chain boot and explicitly want Option 67. I don’t know offhand what those could be, but anyone can do anything in software.
Links
- https://forum.mikrotik.com/viewtopic.php?t=58039
- https://community.ui.com/questions/Network-Boot-adding-characters-to-file-name/cffe7862-dbc7-42e8-bb09-1ef3366fef9c
- EDK II reference: https://github.com/tianocore/edk2/blob/master/NetworkPkg/UefiPxeBcDxe/PxeBcDhcp4.c
- UEFI 2.6 Specification: https://uefi.org/sites/default/files/resources/UEFI%20Spec%202_6.pdf
Tags: pxe, uefi




















{kind=link}